Published: Oct 10, 2024
Spoilt for choice: a guide to selecting an LLM
Executive summary
Final week of July 2024 marked a pivotal moment for open-source AI development, with two major advancements pushing these models to the forefront of technological innovation and potentially broadening access to advanced AI tools. First, Meta’s CEO, Mark Zuckerberg, introduced Llama 3.1, a leading-edge model made freely available to everyone. Just a day later, Mistral, a French AI startup, unveiled Mistral Large 2, a strong competitor to the top AI models. The convergence of this new generation of LLMs with the growing GenAI excitement of business executives since ChatGPT’s release signals a paradigm shift in the development of LLMs that will result in:
- a movement from consumer to enterprise applications;
- a greater demand for domain-specific models over general-purpose models; and
- the emergence of open-source models with permissive licenses that could spark new levels of innovation.
As the landscape of available LLMs gets more crowded by the day, companies looking to explore LLMs and GenAI face an increasingly difficult, but fundamental, question: Which LLM should I choose? This article proposes a lens through which companies can gain perspective and make an informed decision.
To navigate the sea of LLMs successfully, awareness of the different characteristics these models have is crucial. Specifically, it is important to understand if the model is:
- general-purpose or domain-specific;
- proprietary or open-source; and
- deployed as an API, in the cloud, or on-premises?
A deep understanding of one’s use case is required to match the right model characteristics to the application requirements. Questions to be answered include:
- Am I using GenAI to automate a process, or to assist a person’s completion of a task;
- What is the value-at-stake for the target use case;
- Does my use case require specific industry knowledge; and
- What are the necessary security requirements for my use case? Understanding the use case will allow companies to identify the suitable characteristics their chosen LLM must offer. However, there are other design considerations that must also be addressed.
On the business side, executives should conduct a cost-benefit analysis to understand if the adoption of GenAI will boost or hamper value creation. Should GenAI potentially be a major disruptor to their industry, companies should also identify the areas of competitive advantage on which they can capitalise. Lastly, companies must be aware of the reputation of the LLM vendor, and the level of support they will receive in running their LLMs.
The technical considerations fall into three distinct categories. First, for data, companies must select their LLMs in accordance with their data sensitivity and security requirements, and with data availability, a key enabler for the option of fine-tuning. Next, companies must also be cognisant of the model’s performance on benchmarks, as well as how permissive the model license is, especially so in cases of potential competitive advantage. Finally, deployment options must also be closely considered, and companies need to be aware of the trade-off between security compliance and infrastructure investment.
At the current state of LLM development, it is highly unlikely that companies will be able to identify a ‘silver bullet’ LLM that will provide for all their GenAI needs. But having this informed perspective into evaluating and assessing LLMs will enable companies to explore the available options competently and confidently, and to also make the switch when a golden opportunity presents itself in the future.
Generative AI and current trends
An internal Google memo, that was leaked in May 2023, claimed that Open Source AI would outcompete Google and Open AI, summed up simply with the phrase: “we have no moat”1.
The release of Meta’s LLaMA models gave open-source LLM development impetus, which has led to the creation of models that have shown to be able to ‘punch above their weight,’ doing much more with much less. Open-source development, far from being a sideshow to the research efforts of Big Tech corporate labs, has begun to pave a crucial, divergent path in the space of LLM creation and development.
That divergent development, compounded with the growing excitement of business executives for Generative AI (GenAI) following the release of ChatGPT, has resulted in three key shifts in the GenAI and LLM market that we believe will have a profound impact on businesses. Namely, (1) increased business adoption of GenAI; (2) divergent trends in LLM development (general purpose vs. task-oriented); and (3) a notable change to permissive open-source LLM licenses.
Business executives are now flocking to implement some form of GenAI in their companies in the hope that it can help them to improve their business outcomes. Seeing a growing market of unmet demand, some GenAI startups have pivoted their solutions from the consumer to the enterprise space. Tome, a startup that offers an AI-powered tool designed to help users create dynamic, visually compelling narratives without the need for traditional slide decks, shifted its focus from consumer products to more revenue-generating enterprise space2.
As industries continue to bring their GenAI use cases forward, there is a divergent trend in how LLMs are being developed. While LLM development has generally been dominated by hyperscaler LLMs, there is also a wave of industry-specific LLMs that are being trained with industry knowledge to perform better on high value use cases. Open-weight models such as Codestral, code-specific LLM released by Mistral, are challenging products such as GitHub CoPilot by driving the adoption of self-hosted coding assistant3.
As open-source communities find their footing to compete with Big Tech resources, we observe that more permissive open-source LLM licenses are gaining traction.
Rapid proliferation of LLMs
As it stands, the landscape of LLMs is crowded, and will get even more so week by week. Companies intending to explore the capabilities of LLMs are faced with a simple but fundamental question: Which one? The rapid proliferation of LLMs in the market, because of GenAI hype, is leading to ‘choice overload.’ We believe that deeper clarity in how to understand the characteristics of these new models will help companies to make more informed decisions.
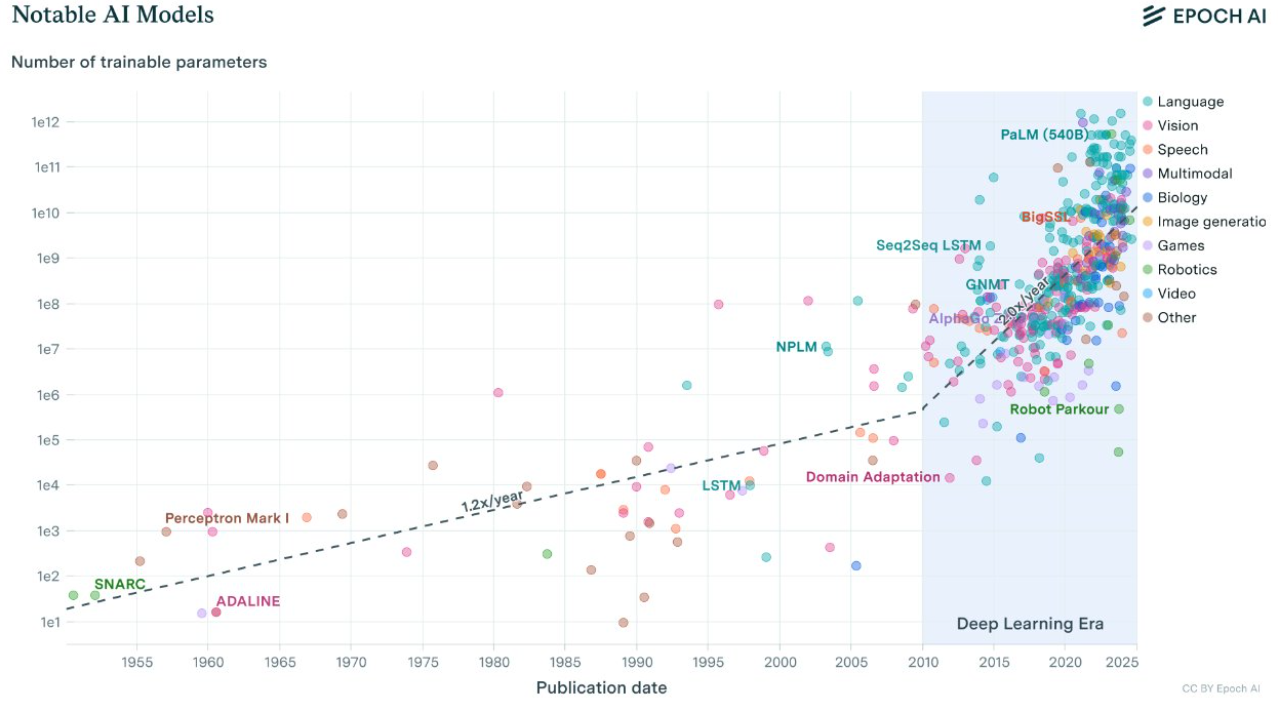
Figure 1. Prominent AI models for different modalities and their growth in number of weights or trainable parameters. Source: Epoch AI 15 August 2024.
These considerations span across the model type, use case, business design and technical design, and have been detailed out in the next few sections.

Figure 2. Overview of framework for selecting an LLM
Model characteristics
General-purpose vs. domain-specific
Almost all the most noteworthy LLMs, including GPT-4, Claude, Gemini, and most recently, Llama 3.1, are general-purpose models. Having been trained on material scraped from the internet, these models can perform a wide variety of tasks, on an endless range of topics, and are like an AI-powered encyclopaedia virtual assistant. A user would just need to be able to prompt the model properly to get the desired output and information. It is the seemingly limitless capabilities of these models that have driven much of the excitement surrounding LLMs.
However, there are other LLMs trained with a specific context or industry in mind. Some examples include Med-PaLM for medical knowledge and Codestral for coding applications. These models are trained to be more accurate and reliable for a chosen field or use case and are more like subject matter experts for that industry.
Proprietary vs. open source
Many of the early LLMs were also proprietary, with the companies doing research on them mainly publishing research papers, and only providing limited access on request to selected users. This behaviour has continued until today, with many noteworthy models not fully released to the public with access restricted through an API. For the most part, interaction with these models is done via prompt engineering, but there are providers who also allow for some customisation through fine-tuning.
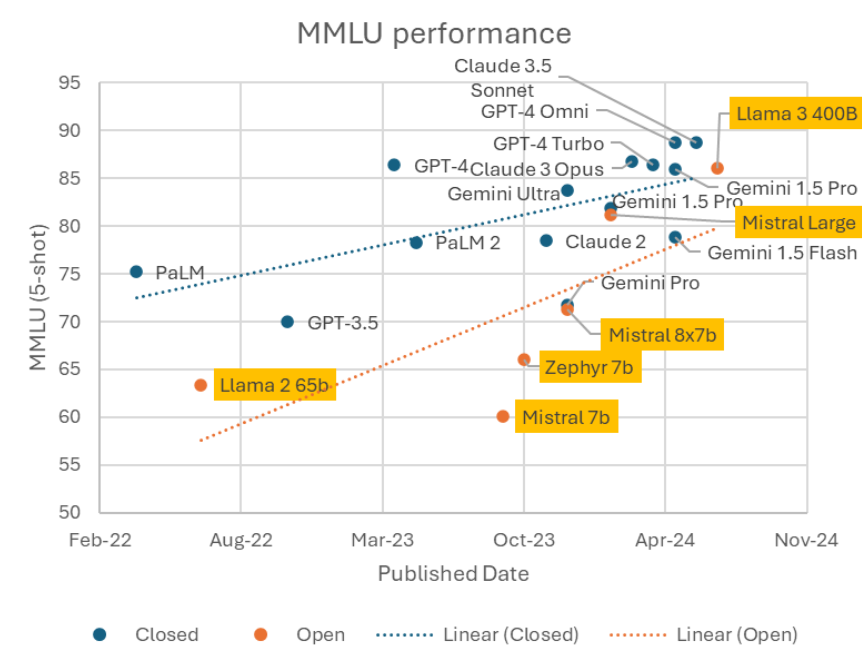
Figure 3. Open-weight models closing the gap with closed models. Source: Maxime Labonne, Twitter, 25 July 2024.
In recent times, however, open-source communities have begun to catch and have developed high-performing models that can compete with the performance of proprietary LLMs. Offering varying degrees of license permissiveness, the creators of these models allow anyone to be able to download the actual model file, and experiment with it, enabling greater flexibility and customisability, not just in terms of the model outputs, but also in deployment.
API vs. cloud vs. on-premises hosting
In terms of deployment, LLMs have been deployed in many ways. For proprietary models like GPT-4, users do not have direct access to the models themselves but interact with them through an API using prompt engineering. Users can pay for API usage through a subscription or on a pay-per-use basis, where the user pays for tokens which are consumed when prompting the model and when generating the content requested. One concern over the use of an API is the lack of trust regarding the security of the application in handling the data being fed into it.
Other providers can help users to host their custom models on a private cloud. Under this option, users are generally able to fine-tune their models as well as ensure data is not being mismanaged, all while not having to invest in expensive compute infrastructure. While this helps to address the concern of data privacy and customisation, users are expected to pay for all the services they require, which includes fine-tuning costs on top of the inferencing costs. In addition, a custom model that has been fine-tuned with the user’s data is not considered the intellectual property of the user themselves.
If the data required to prompt the model is extremely sensitive, or if there is a critical need to protect a user’s IP to maintain competitive advantage, users can opt to host their LLM on-premises. While this option gives the user a greater level of flexibility and control over the LLM, the data, and the resulting IP, it comes with its own set of challenges including the need to invest is expensive compute infrastructure, substantial engineering, and the recruitment or training of talent to ensure the LLM’s capability to affect business outcomes. To address this, infrastructure technology providers are building tools to reduce the complexity of solutions and to increase developer productivity. In March 2024, NVIDIA announced NIM (NVIDIA Inference Microservices), a set of easy-to-use microservices designed to accelerate the deployment of generative AI models across the cloud, data centres and workstations4.
Use case requirements
To effectively identify which LLM is most suitable, a good understanding of the requirements of the use case is crucial. While each use case will be unique, there are helpful ways to examine use cases to gain clarity about pain points and how the LLM can be integrated to address those points.
Domain knowledge
There are potential use cases that will require very specific domain knowledge such as those in the medical, legal, and coding industries, to name a few. The knowledge and training requirements of the model will limit the suitable LLMs available, and it is also possible that no LLM has yet been trained on the desired knowledge base. If a readily available domain specific LLM cannot be found, other options, such as fine-tuning a base LLM, will need to be explored.
GenAI purpose (automate vs. assist)
One key consideration for integrating GenAI is understanding the degree of automation required for the particular use case. If it can be expected that the model will be left to automate some processes on its own, the tolerance for error will be low. On the other hand, if the GenAI solution is there to assist users in completing their tasks, having that human-in-the-loop to curate and screen the model’s outputs will mean that the tolerance for error will be much higher. Knowing how GenAI fits into the workflow of operations will help users understand what level of performance is expected from the LLM and if additional measures like fine-tuning are necessary.
Value-at-stake
A closely related consideration is the value-at-stake of the use case itself. If the use case is one where there is high value-at-stake (i.e., large contract amount, medical applications), the error tolerance will be very low, so the output of the LLM used must be very reliable so as not to jeopardise the solution. But if the use case’s value-at-stake is much lower, the inherent variance of model output can be acceptable and an LLM that performs just ‘well enough’ can be tolerated.
Security
Some use cases may deal with highly sensitive matters, such as personal or high value information, or possibly national security interests, in the case of government agencies. In these situations, the security of the data used for prompting and fine-tuning, as well as the model outputs themselves, must be treated with the utmost vigilance. The security requirements of the use case will affect the chosen deployment method, which then affects the range of suitable LLMs available to the user.
With a deeper understanding of the use case, selecting a suitable LLM with characteristics that match the requirements becomes a simpler task. Use cases that require a high reliability of model outputs will require an LLM that has been proven to perform at a high level. If none are available, selecting an LLM that supports fine-tuning becomes crucial. Use cases that require specific domain knowledge will be best served either by existing LLMs that are already trained with the necessary data, or by LLMs that can be fine-tuned to meet that requirement. Use cases that have high security requirements will necessitate either a private cloud environment or even on-premises hosting to ensure the necessary security standards.
Additionally, there are other design considerations that companies must take into account in evaluating, and ultimately selecting, an LLM.
Business considerations
Fundamentally, the use of the LLM should help an organisation to better achieve its business outcomes. Implementing GenAI, without a clear vision, will create distractions instead of creating value. One key calculation for companies looking to implement GenAI is a cost-benefit analysis. Balancing the capital expenditures (compute resources, GPUs) and operating expenses (licensing fees, salaries) of investing in LLMs with the value they create in terms of cost savings, productivity, or new revenue is critical, and companies should begin with the end in mind, and aim towards a positive return on investment. An interesting trend is LLM providers are passing on the gains from optimised implementations and decreasing cost of hardware to customers by charging less even as model performance rises.
A significant trend to note is the reduction in prices by large language model providers for their customers. This is due to enhanced efficiency in implementation and decreasing hardware costs, even as the performance of these models continues to improve. The cost to achieve an Elo rating of 1250 has dramatically dropped by a factor of 100, from roughly $30/million tokens for Claude 3 Opus in March 2024 to $0.30/million tokens for gpt-4o-mini in July 20241. Following a recent price cut by OpenAI, GPT-4o tokens are now priced at $4 per million tokens, based on a blended rate that assumes 80% input and 20% output tokens. When GPT-4 was initially released in March 2023, it cost $36 per million tokens. This price reduction over a span of 17 months equates to an approximate 79% annual drop in price.
Another consideration is the degree to which implementing GenAI will generate a competitive advantage for the business. If the integration of GenAI can potentially be a key differentiator, or if GenAI could be disruptive to one’s own industry, companies would be well-advised to explore LLMs closely to ride the wave of disruption, or risk sinking instead. Being cognisant of the shifting trends will help industry executives anticipate the opportunities and threats that GenAI will pose to their businesses.
Finally, executives should also consider the reputations of the vendors providing LLMs. Working with LLMs can be a tricky process, and the level of support provided by the vendor is crucial to a successful exploration. For open-source LLMs, having clear documentation and community support will go a long way toward simplifying the installation and deployment processes.
Technical considerations
There are numerous technical considerations that companies must also be aware of in selecting an LLM, among which data management and security are key. Not all LLMs can be integrated into a secure environment, so selecting an LLM that can be hosted securely will be crucial for companies that possess a lot of sensitive data. Data availability is another important consideration when selecting an LLM. A company that has large amounts of high-quality data can leverage their data resources to engineer better prompts, or even perform fine-tuning, and should select an LLM that can support this capability.
For use cases that require higher model output reliability, it may be better to explore a customisable model that can be fine-tuned for a specified use case using proprietary data. If data is not as readily available, companies should target LLMs that have performed well against common benchmarks. In the case of open-source models, if the resulting solution will potentially become an important source of competitive advantage, LLMs with more permissive licenses should be considered ahead of those that are less permissive, so that the IP can be protected.
Another important factor is the benchmarking performance of the LLMs. There are currently different benchmarks available that are used to evaluate and rank the performance of LLMs on various applications and use cases and are equated to standardised testing for language models. Leaderboards, such as those prepared by LMSYS5 and Hugging Face6, provide visibility by creating a snapshot of the benchmarking performance of various LLMs in comparison to each other. Companies must also note that while benchmarks may be helpful tools in comparing LLM performance, they do not have the inherent ability to evaluate the quality of the content generated by the models in real world situations which is a difficult task and remains an open research challenge.
If ensuring data privacy or IP protection is critical, companies should consider LLMs that can be deployed in secure environments. Additional deployment considerations are the necessary operational requirements of the model, such as the compute infrastructure and engineering effort required, and the talent needed to execute the various LLM operations. Companies must be aware of the resources currently available to them and decide if they would prefer to invest in more resources to use a larger, more complex model, or to find a model that can be deployed given their existing levels of resources.
At the current state of LLM development, it is highly unlikely that companies will be able to identify an LLM that is a potential “silver bullet” for all their GenAI needs. Complex use cases may even require the deployment of a portfolio of LLMs, used in concert, to produce the desired output, provided that available resources allow for the use of multiple models.
Conclusion
The framework proposed should help businesses to objectively assess available LLMs and to decide on one (or a few) to explore and, we hope, make the process less daunting. Selecting an LLM is just one of the initial steps and should not become a roadblock in the exciting process of GenAI exploration.
As this space continues to evolve rapidly, having an informed perspective on one’s use case and the available LLMs will be crucial for companies in distinguishing between noise and necessity. Most of the new releases should not delay or derail a company’s planned exploration of GenAI using a selected LLM, but keeping a keen eye on ongoing LLM releases and developments will help companies to identify important switching opportunities as and when they present themselves.